Today we are going to study some concepts closely related to hashmaps. The concepts we are going to see are hashing and collisions.
Hashing
The idea of hashing with chaining is to create a sort of array of lists, into which the elements are somehow inserted.
We need to map the keys to each node to figure out where the array should be placed.
The position of the k key is determined by a function:
h: U --> {0, ..., m-1}
where U is the universe of the represented data and m is the size of the array.
This function is called a hash function.
Esempi di funzioni di hash
A very simple way of hashing string type keys is to consider ASCII codes and make the sum "weighed", using 128 as a base. Let's see better, using the word "oca", which stands for goose, as an example.
oca --> 111 · 128^2 + 99 · 128^1 + 97 · 128^0
This procedure is a bit reminiscent of the decimal conversion procedure from a b base.
Division method
The division method is the hashing method that requires less implementation effort, but at a performance level does not offer a great level of performance. The academic advantage is that it doesn't require much code to work.
The function is as follows:
h(k) = k mod m
where k is the key to map and m is the size of the array within which to map the keys.
Metodo della moltiplicazione
The multiplication method consists of calculating the product:
h(k) = floor(m * (kA - floor(kA)))
A is a real number. It has been demonstrated that a good approximation of A is A = (sqrt(5)-1)/2 = 0.6180339887.
Implementation of a hash function
Let's now see how you can implement the hash function with the C division method.
Header file
int hash_with_div_int(int *key, int size);
The function takes a integer pointer as a parameter, representing the key to map and the size of the array within which to map the key.
Implementation
int hash_with_div_int(int *key, int size){
return *key % size;
}
This function implements exactly the division method explained above. You need to dereference the pointer because the module is calculated with respect to the value of the key and not the address.
Collisions
The technique of hashing with chaining has several advantages, but at the same time it brings to light a problem that must be managed.
- we reduce the space used
- we lose the direct correspondence between keys and positions
- m < |U| and therefore inevitably there may be collisions
By collision we mean the fact that two keys can be mapped in the same position.
Hypothetically, if you have to map keys 10 and 110 having m = 100, both will be mapped in position 10.
There is a theoretical concept that would ideally allow for no collisions. The concept is that of perfect hashing.
Perfect hashing
A hash function is said to be perfect if it never creates collisions. Formalizing the idea we have that:
k1 ≠ k2 ⇒ h(k1) ≠ h(k2)
This is a purely theoretical concept.
Chaining
Chaining is the mechanism by which we manage collisions. It means that instead of inserting one element for each position in the array, we concatenate all collision-generating elements in a list.
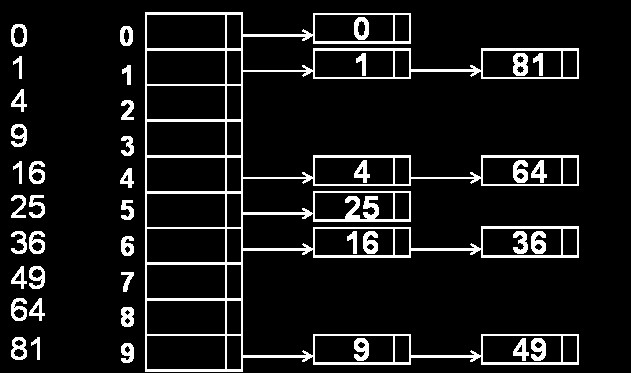
This technique makes it possible to manage collisions efficiently. The insertion operations are carried out in constant time, from the moment when, as I showed in the overflow list article, the pointer is maintained at both the head and tail.
Simple uniformity
Another concept strongly linked to hashing is the concept of simple uniformity.
To say that a hash function has the property of simple uniformity means that the h function distributes the values evenly between cells.
Example
U = {00, 01, ..., 99}
m = 10
h(k) = k mod 10
This function enjoys the property of simple uniformity because each value appears exactly ten times and each cell is the destination of ten keys.
Implementation of hash tables
Creating a new hashmap
hashmap *create_new_map(int s){
hashmap *map = (hashmap*)malloc(sizeof(hashmap));
map -> items = (overflow_list**)malloc(s*sizeof(overflow_list*));
for(int i = 0; i < s; i++){
map -> items[i] = create_empty_doubly_linked_list();
}
map -> size = s;
return map;
}
This function acts as a constructor for a new hashmap. Then, after allocating a pointer for the map, you allocate the space needed to hold the overflow lists, reserving enough space for as many lists as the s parameter.
Then you initialise all lists as empty lists, using the written function for double concatenated lists.
Insertion of a new association
As with any data structure, there is a need to perform input operations. In this particular case, the characteristic is that we do not want duplicate elements, so the complexity of the insertion is higher than that of the algorithm presented in the overflow lists. This is because the insertion is accompanied by a key search.
void insert_association(hashmap *map, void *key, void *val,
HASHFUNC hash,CMPFUNC compare){
int i = hash(key, map->size);
node_t *list = map -> items[i] -> head;
if(contains_key(list, key, compare)==NULL)
insert_item(map->items[i], key, val);
}
The important thing is that among the parameters we have a hash function and a comparison function.
These two parameters are precisely what we need to do when searching, entering and calculating the index.
Extracting the value given a key
void *retrieve_value(hashmap *map, void *key,
HASHFUNC hash, CMPFUNC compare){
int i = hash(key, map->size);
node_t *retrieved;
node_t *h = map -> items[i] -> head;
retrieved = contains_key(h, key, compare);
return retrieved != NULL ? retrieved -> data : NULL;
}
This function allows you to retrieve the value stored in a node given its key. Then calculate the position of the array within which you should find your key.
Then we perform the search and, based on the result, return NULL if the key has not been found, the date field otherwise.
With this technique, the search in a hashmap is reduced to a search in an overflow list, an algorithm we already know.
Removing an association from a hashmap
The last fundamental algorithm to know is that of removing an association.
void delete_association(hashmap *map, void *key,
HASHFUNC hash, CMPFUNC compare){
if(map != NULL){
int i = hash(key, map->size);
remove_item(map->items[i], key, compare);
}
}
Here, if the map is nothing, we calculate the position of the array within which to look for the item and then the algorithm to execute is to remove it in an overflow list.
We can see how even here the deletion can be reduced to the deletion in a list, requiring virtually no implementation effort.
I hope you enjoyed this lesson on hashmaps. I invite you to personally implement the code I propose and who knows, maybe you will have some suggestions.
See you next time![]()
