Bentornati in questa nostra panoramica sul mondo Java! Oggi andremo a parlare di un algoritmo di ordinamento tra i più celebri. Il Quick Sort.
A differenza del precedentemente trattato Bubble Sort, Quick Sort non si presta particolarmente a fini didattici siccome la sua implementazione potrebbe non risultare banale, ma a livello prestazionale offre vantaggi non indifferenti.
Cerchiamo di capire meglio di cosa si tratta.
Prima di tutto, vediamo un'illustrazione che ci da un'idea sommaria di cosa fa l'algoritmo.
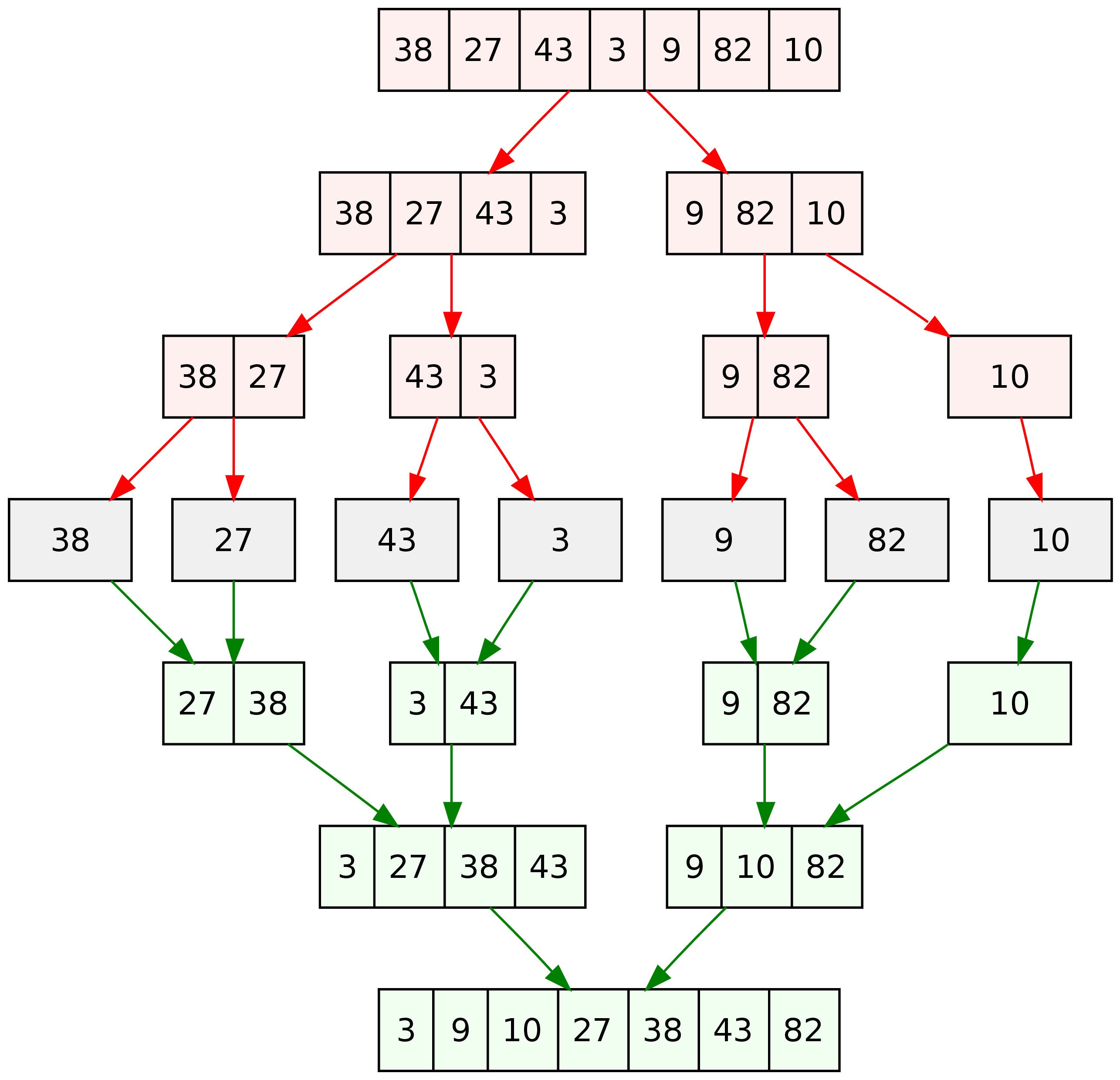
Caratteristiche fondamentali e descrizione
Il Quick Sort è uno degli algoritmi di ordinamento più utilizzati, specialmente quando si ha a che fare con grandi quantità di dati. Come altri algoritmi, fa parte della famiglia Divide and Conquer (dividi e conquista).
Significa che il lavoro non viene svolto sull'intera collezione di dati, ma viene bensì svolto ricorsivamente su sottoinsiemi finiti della collezione. Questo permette di rendere più leggere le operazioni di ordinamento dal momento in cui i valori da confrontare sono al più due.
Ricordiamo che il Quick Sort è un algoritmo stabile e soprattutto in-place. Generalmente nessun algoritmo è stabile, ma può essere reso stabile usando gli indici come metro di paragone.
Vediamo quali sono i passi principali dell'algoritmo.
Se la collezione contiene zero elementi o un elemento, allora è ordinata. In caso contrario si eseguono i seguenti passi:
- Si sceglie un pivot;
- Gli elementi della collezione sono divisi in due parti: quelli prima del pivot e quelli dopo il pivot;
- Si ordinano gli elementi ripetendo ricorsivamente i passi 1 e 2;
Implementazione
import java.util.*;
public class QuickSort
{
/*
Questa funzione prende l'ultimo elemento come pivot,
piazza l'elemento di pivot nella sua posizione corretta
nell'array ordinato. Inoltre piazza tutti gli elementi
"più piccoli" del pivot a sinistra e tutti quelli
"più grandi" alla destra del pivot.
*/
private static int partition(int arr[], int low, int high)
{
int pivot = arr[high];
int index = (low-1); // indice dell'elemento più piccolo. -1 all'inizio
for (int j=low; j array da ordinare,
low --> indice iniziale,
high --> indice finale */
public static void sort(int arr[], int low, int high)
{
if (low < high)
{
/* pi è l'indice di partizionamento, arr[pi] è ora al
posto giusto */
int pi = partition(arr, low, high);
// Ordina ricorsivamente gli elementi prima di
// partition e dopo partition
sort(arr, low, pi-1);
sort(arr, pi+1, high);
}
}
// Programma guida.
public static void main(String args[])
{
int arr[] = {10, 7, 8, 9, 1, 5};
int n = arr.length;
QuickSort.sort(arr, 0, n-1);
System.out.println("sorted array");
System.out.println(Arrays.toString(arr));
}
}
Capiamo il codice
L'elemento cardine è la scelta del pivot ("perno"). Il pivot ideale sarebbe l'elemento medio della collezione, che però è difficile trovare se non si ha un insieme di elementi ordinati. Per cui le scelte possono essere differenti. Si può scegliere come pivot sempre il primo elemento, l'ultimo elemento, l'elemento in posizione centrale o un elemento random.
Il metodo principale è il metodo partition che prende come parametri la collezione da ordinare, in questo caso un array di numeri interi, e i due estremi di ordinamento left e right.
All'interno di questo metodo vengono fatte tutte le operazioni di scambio ed è il metodo che implementa l'algoritmo.
Il corpo del metodo contiene semplicemente delle operazioni di scambio effettuate solo in certe condizioni. Il principio molto elementare è che è inutile scambiare due elementi già ordinati, quindi si fa il controllo tra il pivot e l'elemento j.
Gli indici hanno il seguente significato:
- i indica l'elemento più piccolo che si è esaminato;
- j indica l'elemento corrente;
Il metodo sort non fa altro che fare da metodo wrapper a partition. Viene effettuato il controllo su low e high per verificare che "abbiano senso" e che non si verifichino situazioni dove low=2 e high=1 in virtù del fatto che si verrebbero a creare situazioni inconsistenti.
Viene inoltre calcolato il partition index, ovvero l'indice di partizionamento.
Abbiamo infine il main, dove viene creato l'array da ordinare. Successivamente viene richiamato il metodo sort sull'array e con indici 0 e n-1 (dove n indica la lunghezza dell'array).
Precisiamo che ho scelto volutamente di rendere statico il metodo sort. Ho deciso di fare questo perchè ho immaginato il codice presentato sopra come parte di una classe più grande che implementa più algoritmi insieme. Di conseguenza, essendo sort statico, lo deve essere anche partition.
Si sarebbe potuto tranquillamente creare un metodo non statico da richiamare su un oggetto di tipo QuickSort.
Chiaramente, come nella maggior parte delle situazioni che si presentano in informatica, ci sono diverse varianti dell'implementazione de Quick Sort. Tutte hanno lo stesso risultato finale. Ciò che cambia sono i dettagli implementativi.
Cenni sulla complessità
Il tempo impiegato dal QuickSort può essere espresso come:
T(n) = T(k) + T(n-k-1) +(n)
I primi due termini sono le due chiamate ricorsive e k indica gli elementi minori del pivot. Il tempo effettivo dipende dalla scelta del pivot. Vediamo alcuni
casi notevoli.
Caso peggiore:
T(n) = T(n-1) +
Accade quando si prende come pivot sempre l'elemento più grande o l'elemento più piccolo
La complessità è assimilabile a (n2). Notiamo come qui la complessità sia esponenziale.
Caso migliore:
T(n) = 2T(n/2) +
Qui la complessità è assimilabile a (nLogn).
Caso intermedio:
T(n) = T(n/9) + T(9n/10) +
Per fare un'analisi accurata della complessità nel caso intermedio, bisognerebbe calcolare tutte le possibili permutazioni degli elementi della collezione e non è per niente facile. Ci si può fare un'idea della complessità considerando il caso in cui partition mette O(n/9) elementi in un set e O(9n/10) elementi nell'altro.
La complessità è assimilabile a (nLogn) anche in questo caso.
Curiosità: che cos'è il three-way-quick-sort?
Il three-way-quick-sort è una versione del Quick Sort dove la collezione da ordinare viene divisa così come segue:
- array[low...i] è l'insieme degli elementi minori del pivot;
- array[i...j-1] è l'insieme degli elementi uguali al pivot;
- array[j...high] è l'insieme degli elementi maggior idel pivot;
E' evidente che questa versione sia conveniente solo quando ci sono diversi elementi ridondanti nella collezione. In caso contrario sarebbe priva di senso.