In questa breve serie di articoli andremo a vedere com'è possibile realizzare in C la struttura dati Hashmap.
Nell'implementazione andremo ad usare le liste doppiamente concatenate come strutture dati ausiliarie. Andiamo a vedere una possibile implementazione.
Header file
Vediamo prima di tutto com'è fatto il file .h.
Definizione di un nodo
Definiamo la struttura dati nodo come segue:
typedef struct node_t{
struct node_t *prev;
struct node_t *next;
void *data;
void *key;
}node_t;
Stiamo definendo quindi un nuovo tipo dati node_t. Questa nuova struttura è composta da 4 campi:
- prev, che rappresenta il predecessore del nodo all'interno della lista;
- next, che rappresenta il nodo successivo all'interno della lista;
- data, cioè l'informazione rappresentata dal nodo;
- key è invece la chiave identificativa del nodo;
Entrambi i campi key e data sono stati dichiarati come puntatori a void siccome l'idea è quella di realizzare del codice generico, utilizzabile in qualsiasi circostanza.
Definizione del tipo dati lista
La lista avrà una definizione come:
typedef struct overflow_list{
node_t *head;
node_t *tail;
} overflow_list;
L'idea è quella di mantenere un puntatore alla testa della lista e anche alla coda, in modo da eseguire in tempo costante gli inserimenti in testa e in coda.
Altre definizioni utili
Sarà utile fare queste due typedef.
typedef int (*CMPFUNC)(const void *, const void*); typedef void (*PRNTFUNC)(const void *);
La prima definizione dichiara un puntatore a funzione che chiamo CMPFUNC che ha come parametri due puntatori a void. Questa funzione servirà più avanti per poter comparare i due parametri i quali, nell'implementazione reale, avranno tipi ben definiti.
La dichiarazione di PRNTFUNC serve a dichiarare il tipo di una funzione che si occupa di stampare un puntatore. E' necessaria siccome l'applicazione che ho realizzato effettua stampe su linea di comando mendiante printf, motivo per cui abbiamo bisogno di sapere di che tipo è il dato che si vuole stampare.
Tutte le funzioni di cui fornirò l'implementazione devono avere una corrispettiva dichiarazione nel file header.
Implementazione delle funzioni
Creazione di un nodo
La prima cosa di cui abbiamo bisogno è avere a disposizione una funzione comoda per poter creare un nuovo nodo.
node_t *create_node(void *k, void *d){
node_t *n = (node_t*)malloc(sizeof(node_t));
n -> data = d;
n -> key = k;
n -> next = NULL;
n -> prev = NULL;
return n;
}
create_node prende come parametro due puntatori a void k e d che rappresentano rispettivamente la chiave e il dato memorizzati nel nodo. Dopo aver eseguito la malloc per allocare lo spazio necessario, assegniamo i parametri ai rispettivi campi del node_t appena creato. I campi next e prev sono settati a NULL siccome il nodo non è ancora stato inserito nella lista, per cui non sappiamo ancora che valore avranno quei due campi.
Creazione di una lista
overflow_list *create_empty_doubly_linked_list(){
overflow_list *l = (overflow_list*)malloc(sizeof(overflow_list*));
l -> head = NULL;
l -> tail = NULL;
return l;
}
Questa funzione funge da "costruttore" per la lista, andando ad allocare lo spazio apposito per la lista e settando sia la coda che la testa a NULL.
Il motivo, per quanto banale, è che una lista vuota non contiene elementi, per cui i due campi saranno nulli.
Inserimento di un elemento nella lista
void insert_item(overflow_list *l, void *k, void *v){
node_t *n = create_node(k, v);
if(l->head == NULL){
l->head = l->tail = n;
}else{
l->tail->next = n;
n->prev = l->tail;
l->tail = n;
}
}
La cosa importante da capire è il significato dei parametri. La lista l rappresenta la lista all'interno della quale vogliamo effettuare l'inserimento. I campi k e v sono i dati che andranno memorizzati nel nodo che inseriremo. Qui non ci si preoccupa della presenza o meno di duplicati nella collezione. Più avanti vedremo un modo per evitare l'inserimento di elementi duplicati.
L'algoritmo è quello degli inserimenti in coda, che può essere eseguito in tempo costante proprio grazie al mantenimento e aggiornamento del puntatore alla coda della lista.
Ricerca di una chiave
Vogliamo realizzare una funzione che ci dica se un elemento è presente o meno in una lista, effettuando una comparazione sulle chiavi.
node_t *contains_key(node_t *head, void *k, CMPFUNC compare){
while(head!=NULL && compare(k, head->key) != 0){
head = head->next;
}
return head != NULL ? head : NULL;
}
L'idea è quella di scorrere la lista fino a quando non si trova l'elemento in questione oppure gli elementi della lista non sono terminati.
Abbiamo necessità della funzione di comparazione compare siccome non possiamo comparare direttamente due puntatori a void. Al termine del metodo restituiamo il puntatore al nodo che abbiamo trovato se non vale NULL. Restituiamo NULL altrimenti.
Rimozione di un elemento
Per implementare la rimozione ho definito due funzioni ausiliarie che si occupano di rimuovere l'elemento dalla testa o dalla coda.
Cancellazione in testa
Vediamo l'algoritmo di cancellazione dalla testa di una lista.
void remove_from_beg(overflow_list *l){
node_t *temp;
if(l->head == NULL){
printf("Trying to delete from empty listn");
}else{
temp = l->head;
l->head = l->head->next;
if(l->head!=NULL){
l->head->prev = NULL;
}
temp->next=NULL;
free(temp);
}
}
L'unica cosa da fare è aggiornare il puntatore alla testa della lista. Ho trovato utile memorizzare il nodo che si sta scollegando dalla lista in modo da poter richiamare la free su quel nodo.
Si aggiorna il puntatore alla testa valorizzandolo con il suo elemento successivo e si imposta il campo prev della nuova testa a NULL.
Cancellazione in coda
void remove_from_end(overflow_list *l){
node_t *temp;
if(l->tail==NULL){
printf("Trying to delete on empty listn");
}else{
temp = l->tail;
l->tail->prev->next = NULL;
l->tail = temp->prev;
free(temp);
}
}
L'idea è similare a quella della rimozione in testa, con l'unica differenza che si aggiorna il puntatore alla coda con il suo precedente.
Anche questa operazione viene eseguita in tempo costante.
Cancellazione in posizione qualsiasi
void remove_item(overflow_list *l, void *k, CMPFUNC compare){
node_t *temp = contains_key(l->head, k, compare);
if(temp == l->head){
remove_from_beg(l);
}else if(temp == l->tail){
remove_from_end(l);
}else{
if(temp!=NULL){
if(temp->prev!=NULL){
temp->prev->next = temp -> next;
}
if(temp->next!=NULL){
temp->next->prev = temp->prev;
}
free(temp);
}
}
}
Questa funzione mette insieme le due funzioni scritte prima, aggiungendo la rimozione di un elemento che non sia in testa e in coda.
Per cui, se l'elemento che vogliamo rimuovere è la testa o la coda della lista, si richiamano le funzioni apposite. Nel caso in cui l'elemento sia centrale, lo disconnettiamo dalla lista come mostra l'immagine qui sotto.
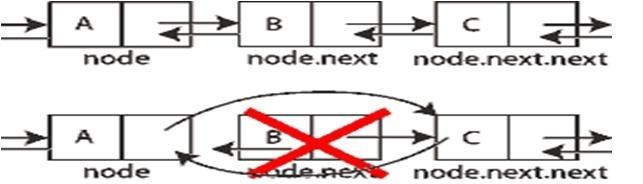
L'idea è quindi di "scollegare" il nodo, eliminandolo così dalla lista, ricucendo poi i link per non scollegare la lista.
Ricerca
Avendo una struttura dati, le operazioni di ricerca sono a dir poco indispensabili.
Le implementazioni che andremo a vedere saranno due: una iterativa e una ricorsiva.
Ricerca di una chiave
node_t *contains_key(node_t *head, void *k, CMPFUNC compare){
while(head!=NULL && compare(k, head->key) != 0){
head = head->next;
}
return head != NULL ? head : NULL;
}
L'idea fondamentale è quella di ricercare un nodo in una lista, scorrendo i nodi uno a uno partendo dalla testa.
La guardia del while ha questo significato: il ciclo continua ad iterare sino a quando il nodo che stiamo esaminando non è uguale a NULL e fino a quando la funzione di comparazione ci restituisce un valore diverso da zero quando compara il parametro k e la chiave del nodo corrente.
Alla fine verrà restituito il valore del parametro head.
Ricerca di un dato
Il principio della ricerca di un dato è esattamente lo stesso di quello della ricerca della chiave. La seguente implementazione è però ricorsiva.
node_t *contains_data(node_t *head, void *d, CMPFUNC compare){
if (head == NULL){
return NULL;
}
else if (compare(head->data, d)==0){
return head;
}
else{
return contains_data(head->next, d, compare);
}
}
Schema generale dello scorrimento di una lista
Nelle operazioni di ricerca lo schema per lo scorrimento della lista è sempre analogo, ed è lo stesso ogni qual volta si devono fare operazioni che richiedono lo scorrimento della struttura.
Vediamo brevemente qual è.
void run_through(overflow_list *l){
node_t *temp = l -> head;
while (temp != NULL) {
temp = temp -> next;
}
}
Abbiamo un nodo temp che funge da cursore. Nel ciclo, mediante l'istruzione temp = temp -> next si sfrutta il campo next del nodo per scorrere i vari nodi.
Nei prossimi articoli andremo a vedere come utilizzare le liste doppiamente linkate per implementare le hashmap.